

cs133(cs131 第一讲 课程介绍)
cs131 第一讲 课程介绍
by:斯坦福大学计算机科学系
github:
zhaoxiongjun/CS131_notes_zh-CN (包含中英文版课件及相关课程视频)
1 什么是计算机视觉?
1.1 定义
计算机视觉有两种定义:计算机视觉可以定义为从数字图像中提取信息的科学领域。从图像获得的信息类型可以是多样的,从识别,空间测量导航或增强现实应用。 定义计算机视觉的另一种方法是通过其应用程序。计算机视觉正在构建可以理解图像内容并将其用于其他应用程序的算法。我们将在第四节中更详细的了解到计算机视觉应用的不同领域。
一点历史:计算机视觉的起源可以追溯到1966年麻省理工学院的本科暑期项目[ 4]。当时人们认为计算机视觉可以在一个夏天解决,但我们现在有一个50年历史的科学领域还远未解决。
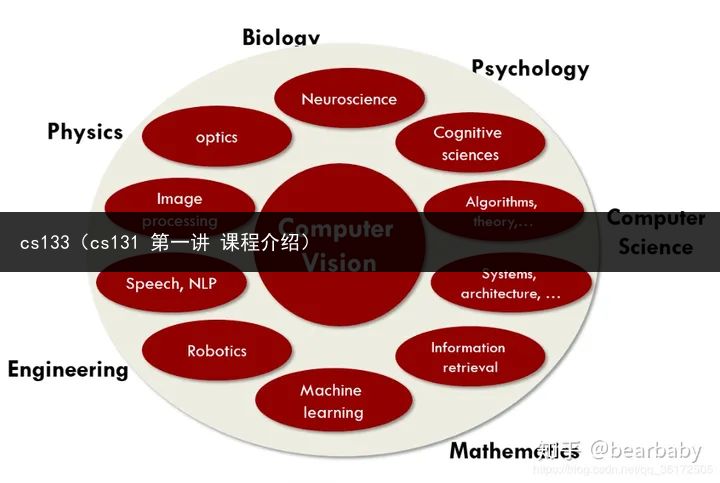
图1:多个科学领域交叉的计算机视觉
1.2 跨学科领域
计算机视觉汇集了大量学科。神经科学首先可以通过理解人类视觉帮助计算机视觉,我们将在第2节中看到。计算机视觉可以被视为计算机科学的一部分,算法理论或机器学习对于开发计算机视觉算法至关重要。我们将在本课程中展示图中1的所有字段是如何连接,计算机视觉如何从中获得灵感和技巧。
1.3 一个难题
计算机视觉在50年内尚未解决,仍然是一个非常棘手的问题。这是我们人类无意识的行为,但这对计算机来说确实很难。
诗歌比国际象棋更难 在1997年,IBM的超级计算机Deep Blue首次击败世界国际象棋冠军加里卡斯帕罗夫。今天我们仍然很难构造一个算法输出的句子很好,更不用说诗歌了。这两个领域之间的差距表明什么是人类智能通常不是评估计算机任务难度的良好标准。深蓝通过数百万种可能性中的蛮力搜索赢得了胜利,而不是比卡斯帕罗夫更聪明。视觉比3D建模更难 今天创建一个精确到毫米级的物体的三维模型比建立一个识别椅子的算法要容易。物体识别仍然是一个非常困难的问题,虽然我们正在接近人类的准确性。为什么这么难? 计算机视觉是棘手的,因为像素和意义之间存在巨大差距。计算机在200×200 RGB图像中看到的是一组120,000个值。从这些数字到有意义的信息的道路是非常困难的。可以说,人类的大脑视觉皮层解决了一个难以解决的问题:理解投射在视网膜上的图像,并将其转换为神经元信号。下一节将展示如何研究大脑以帮助计算机视觉。2 了解人类视觉
解决计算机视觉的第一个想法是了解人类视觉是如何工作的,并将其转化到计算机上。
2.1 视觉的定义
无论是计算机还是动物,视觉归结为两个组成部分。 首先,传感设备从图像中捕获尽可能多的细节。眼睛会捕捉穿过虹膜的光线并将其投射到视网膜,在那里有专门的细胞通过神经元将传递信息到大脑。相机以类似的方式捕获图像并将像素传输到电脑。在这一部分,相机比人类更好,因为他们可以看到红外线,看到更远或更多,而且更精确。 其次,解释器必须处理信息,并从中提取意义。人类的大脑在不同区域以多个步骤解决了这个问题。计算机视觉在这个领域的表现仍然滞后于人类。
2.2 人类视觉系统
1962年,Hubel&Wiesel [3 ]试图通过记录神经元来了解猫的视觉系统,同时向猫展示明亮的线条。他们发现,只有当这条线位于视网膜的特定位置,或者当它有特定的方向时,一些特殊的神经元才会被激活。 他们的研究开启了理解人类视觉系统的科学之旅,在今天仍然活跃。1981年,他们的工作获得了诺贝尔生理学和医学奖。 之后Hubel博士说:“有一个神话说大脑无法理解自己。它被比作一个人试图通过自己的自我提升自己。我们觉得这是胡说八道。该大脑可以像肾脏一样进行研究。”
2.3 人类视觉系统有多好?
速度对于人类视觉系统是非常高效的。意识到威胁并对它们作出反应的迅速能力对生存至关重要,数百万年来,进化完善了哺乳动物视觉系统。在正常的自然场景下,人体视觉系统的速度已被测量[ 7]约150ms来识别动物。图2显示了大脑对动物和非动物图像的反应大约在150ms后发散。

图2:动物和非动物反应之间的差异。来自[ 7 ]
然而,这种速度是以某些缺点为代价获得的。小小的改变图像的不相关部分,如水反射或背景,可能会被忽略,因为人类的大脑专注于图像的重要部分[ 5]。 如果信号非常接近背景,则可能难以检测和分割图像的相关部分。 人类一直使用语境来推断图像的线索。以前的知识(常识和经验)是一个最难以融入计算机视觉的工具。人类利用环境知道应该专注于图像的哪部分,知道在某些特定位置会发生什么。语境也有助于大脑补偿阴影中的颜色。然而,语境可能会误导人类的大脑。
2.4 来自大自然的教训
模仿鸟类并没有将人类引向学会飞行。简单地复制自然并不是学习如何飞行最好的方式和最有效的的方法。但研究鸟类让我们了解空气动力学,并且了解像升力这样的概念让我们能够建造飞机。 智力也是如此。尽管今天的技术无法实现,模拟一个完整的人类大脑来创造智慧可能仍然不是达到目标的最佳方式。然而,神经科学家希望能够深入了解视觉和语言背后的概念和其他形式的智慧。
3 从图像中提取信息
我们可以将从计算机视觉中的图像中获得的信息分为两类:测量 - 和语义信息。
3.1 视觉作为测量设备
在未知位置导航的机器人需要能够扫描周围环境来计算最佳路径。使用计算机视觉,我们可以测量机器人周围的空间并创建它的地图环境。 立体摄像机通过三角测量提供深度信息,就像我们的两只眼睛一样。立体视觉是一种计算机视觉的大领域,目前有很多研究试图在给定立体图像下创建一个精确的地图。 如果我们增加视点的数量以覆盖对象的所有边,我们可以创建3D表面代表对象[ 2]。更具挑战性的想法可能是重建的3D模型是通过谷歌图像搜索这座纪念碑的所有结果创建的[1]。 还有研究抓方面的,计算机视觉可以帮助理解3D几何去帮助机器人抓住它的物体。通过机器人的摄像头,我们可以识别并找到物体的把手并推断其形状,然后使机器人找到一个好的抓握位置[ 6]。 ### 3.2 语义信息的来源 除了测量信息之外,图像还包含非常密集的语义信息。我们可以在图像中标记对象,标记整个场景,识别人物,识别动作,手势,脸部。 医学图像也包含许多语义信息。计算机视觉对此会有帮助。例如,基于皮肤细胞图像的诊断,以确定它们是否是癌性的。
4 计算机视觉的应用
相机无处不在,互联网上传的图像数量呈指数级增长。我们在Instagram上有图像,在YouTube上有视频,有安全摄像头,医疗和科学图像...计算机视觉是必不可少的,因为我们需要对这些图像进行分类,使计算机能够理解它们的内容。这是计算机视觉应用程序的非详尽列表。
特殊效果 形状和动作捕捉是像《阿凡达》这样的电影中使用的新技术。通过记录人类演员所扮演的动作来制作数字角色。为了做到这一点,我们有在3D空间中找到演员脸部上标记的确切位置,然后在其上重新创建它们数字化身。3D城市建模 在城市上用无人机拍照可以用来渲染3D模型城市。计算机视觉用于将所有照片组合成单个3D模型。场景识别 可以识别拍摄照片的位置。例如,可以将地标照片与谷歌上的数十亿张照片进行比较,以找到最佳匹配。我们然后可以识别最佳匹配并推断出照片的位置。人脸检测 人脸检测已在相机中使用多年,以拍摄更好的照片并专注于面孔。微笑检测可以让相机在拍摄时自动拍照 主题在微笑。人脸识别比人脸检测更难,但具有规模今天的数据,像Facebook这样的公司能够获得非常好的表现。最后,我们也可以使用计算机视觉进行生物识别,使用独特的虹膜模式识别或指纹。光学字符识别 计算机视觉最古老的成功应用之一是识别字符和数字。这可用于阅读邮政编码或车牌。移动视觉搜索通过计算机视觉,我们可以使用图像作为搜索在Google上进行搜索查询。自动驾驶汽车 自动驾驶是计算机视觉的最热门应用之一。COM的像特斯拉,谷歌或通用汽车这样的公司竞争成为第一个建立完全自治的公司汽车。自动结账 Amazon Go是一种没有结账的新商店。用电脑视觉,算法准确地检测您采取的产品,当您走出时,它们会向您收取费用商店2。基于视觉的交互 微软的Kinect实时捕捉运动,并允许玩家通过移动直接与游戏互动。增强现实 AR现在也是一个非常热门的领域,多家公司正在竞争提供最好的移动AR平台。苹果公司在6月发布了ARKit并且已经令人印象深刻申请3。虚拟现实 VR使用与AR类似的计算机视觉技术。算法需要知道用户的位置,以及周围所有物体的位置。当用户四处走动时一切都需要以现实和顺利的方式进行更新。References
[1] Michael Goesele, Noah Snavely, Brian Curless, Hugues Hoppe, and Steven M Seitz. Multi-view stereo for community photo collections. In Computer Vision, 2007. ICCV 2007. IEEE 11th International Conference on, pages 1–8. IEEE, 2007. [2] Anders Heyden and Marc Pollefeys. Multiple view geometry. Emerging topics in computer vision, pages 45–107, 2005. [3] David H Hubel and Torsten N Wiesel. Receptive fields, binocular interaction and functional architecture in the cat’s visual cortex. The Journal of physiology, 160(1):106–154, 1962. [4] Seymour A Papert. The summer vision project. 1966. [5] Ronald A Rensink, J Kevin O’Regan, and James J Clark. On the failure to detect changes in scenes across brief interruptions. Visual cognition, 7(1-3):127–145, 2000. [6] Ashutosh Saxena, Justin Driemeyer, and Andrew Y Ng. Robotic grasping of novel objects using vision. The International Journal of Robotics Research, 27(2):157–173, 2008. [7] Simon Thorpe, Denise Fize, and Catherine Marlot. Speed of processing in the human visual system. nature, 381(6582):520, 1996.
~~但行好事,莫问前程~~



